Liên hệ quảng cáo
Đề xuất ứng dụng học máy dự báo TNGT tại Việt Nam
Hiện nay, các nước trên thế giới đã và đang áp dụng mạnh mẽ các thuật toán khác nhau của học máy (Machine Leaning) vào việc phát triển mô hình dự báo về tần suất và mức độ nghiêm trọng của TNGT
TNGT đã và đang là một thách thức đối với toàn cầu. Hiện nay, các nước trên thế giới đã và đang phát triển các mô hình dự báo TNGT để phân tích các yếu tố tác động và dự báo về tần suất tai nạn và mức độ nghiêm trọng của tai nạn nhằm giúp các cơ quan quản lý nhà nước đưa ra các chính sách và giải pháp kịp thời. Các mô hình thống kê truyền thống đã được sử dụng, tuy nhiên còn nhiều những hạn chế về giả định của các mô hình truyền thống này. Để giải quyết vấn đề này, hiện nay, các nước trên thế giới đã và đang áp dụng mạnh mẽ các thuật toán khác nhau của học máy (Machine Leaning) vào việc phát triển mô hình dự báo về tần suất và mức độ nghiêm trọng của TNGT. Kết quả cho thấy rằng, mô hình sử dụng học máy hiệu quả hơn các mô hình dự báo thống kê truyền thống.
Theo báo cáo của Tổ chức Y tế thế giới (WHO) năm 2018, số người chết do TNGT là 1,35 triệu người và TNGT đứng thứ 8 về nguyên nhân gây chết người trên thế giới. Tại Việt Nam, theo báo cáo của Ủy ban ATGT Quốc gia, trong giai đoạn 5 năm (từ năm 2015 đến năm 2020), tổng số vụ TNGT xảy ra là 94.024 vụ, làm chết 39.917 người, bị thương 77.477 người. Số người chết trung bình khoảng 22 người mỗi ngày và khoảng 1 người chết mỗi giờ tại Việt Nam. TNGT tập trung chủ yếu vào giao thông đường bộ. Vì vậy, TNGT đã và đang là một vấn đề thách thức rất lớn đối với các nước trên thế giới và Việt Nam.
TNGT là một sự cố phức tạp do tác động bởi rất nhiều các yếu tố như hạ tầng giao thông, phương tiện, con người và điều kiện môi trường. Hiện nay, trên thế giới đã và đang phát triển các mô hình dự báo TNGT để đánh giá các yếu tố ảnh hưởng đến tai nạn và dự báo tần suất và mức độ nghiêm trọng của tai nạn để giúp các cơ quan quản lý nhà nước đưa ra các chính sách và giải pháp phù hợp nhằm giảm thiểu về TNGT. Hiện nay, Việt Nam chưa có nhiều nghiên cứu sâu về các mô hình dự báo TNGT.
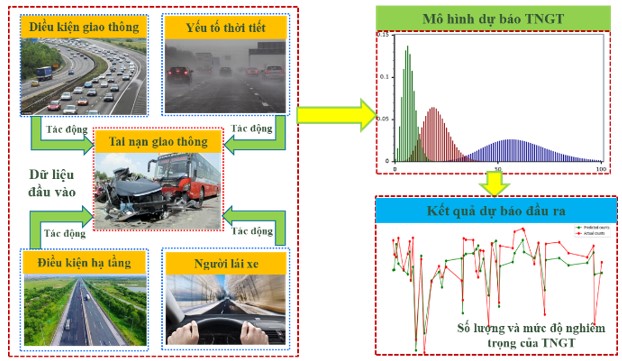
Hình 1: Minh họa về mô hình dự báo TNGT
Các nghiên cứu đã sử dụng các mô hình thống kê truyền thống để phát triển các mô hình dự báo TNGT. Đối với mô hình dự báo về tần suất TNGT, các mô hình được sử dụng rộng rãi bao gồm mô hình hồi quy Poisson (Jovanis et al, 1986; Joshua et al, 1990), mô hình hồi quy nhị thức âm (Chengye et al,. 2013; Ma et al., 2017; Gaweesh et al ,2019), mô hình hồi quy logarit Poisson (Miaou et al, 2005; Lord et al, 2008), mô hình hồi quy Gama (Oh et al,. 2006; Daniels et al. 2010), mô hình ảnh hưởng ngẫu nhiên (Johansson et al, 1996; Shankar et al. 2003)... Đối với mô hình dự báo về mức độ nghiêm trọng của TNGT, các mô hình được sử dụng bao gồm mô hình logit nhị phân (Kononen et al. 2011), mô hình probit nhị phân (Peek-Asa et al. 2010; Ye et al. 2014), mô hình hồi quy probit thứ bậc Bayesian (Xie, Zhang, and Liang 2009)... Tuy nhiên, các mô hình này có các hạn chế về các giả định riêng của từng mô hình, các yêu cầu về phân phối của dữ liệu và cần phải xác định trước mối liên hệ giữa biến độc lập và biến phụ thuộc trong mô hình. Trong trường hợp vi phạm các điều kiện mô hình có thể dẫn đến bị ước tính sai và dự đoán không chính xác (Silva, et al. 2020).
Nhằm giải quyết các hạn chế của mô hình thống kê truyền thống, gần đây các nghiên cứu trên thế giới đã ứng dụng các thuật toán của học máy vào phát triển mô hình dự báo về TNGT. Mục tiêu của bài báo là tổng hợp các thuật toán của học máy trong việc phát triển các mô hình dự báo TNGT mà các nước trên thế giới đang áp dụng và đề xuất, kiến nghị một số thuật toán của học máy phù hợp áp dụng tại Việt Nam.
Học máy trong các mô hình dự báo TNGT
Trong những năm gần đây, sự phát triển của trí tuệ nhân tạo AI (Artificial Intelligence) mà cụ thể là học máy (Machine Learning) là một bằng chứng cho sự phát triển của cuộc cách mạng công nghiệp 4.0. Học máy là một lĩnh vực của trí tuệ nhân tạo liên quan đến việc nghiên cứu và xây dựng các kĩ thuật cho phép các hệ thống "học" tự động từ dữ liệu để giải quyết những vấn đề cụ thể (M. I. Jordan et al. 2015; Batta 2020). Nó được sử dụng rộng rãi trong các lĩnh vực khác nhau như mạng xã hội, y học, kinh tế, giao thông, thương mại điện tử...
Học máy được phân chia thành hai nhóm chính là học có giám sát và học không có giám sát dựa trên phương thức học. Học có giám sát là thuật toán dự đoán đầu ra của một dữ liệu mới dựa trên các cặp dữ liệu (đầu vào, đầu ra) đã biết từ trước. Trong học có giám sát được phân chia thành hai loại chính là phân loại (classification) và hồi quy (regression). Đối với học không giám sát, chúng ta không biết được đầu ra mà chỉ có dữ liệu đầu vào và sẽ dựa vào cấu trúc của dữ liệu để thực hiện một công việc nào đó. Học không giám sát được chia thành hai loại là phân nhóm (clustering) và khám phá quy luật (association).
Hiện nay, các nghiên cứu áp dụng các thuật toán khác nhau của học máy để phát triển các mô hình dự báo về TNGT. Trong mô hình dự đoán TNGT của học máy được phân thành hai mô hình chính dựa theo muc tiêu của dự báo bao gồm mô hình dự báo về tần suất TNGT và mô hình dự báo về mức độ nghiêm trọng của TNGT. Dưới đây trình bày các thuật toán của học máy cho từng loại mô hình.
* Mô hình dự báo về tần suất TNGT:
Mục đích chính của mô hình dự báo về tần suất TNGT là dự báo về tần suất TNGT xảy ra trên một đoạn đường, nút giao dựa trên dữ liệu về lịch sử của TNGT. Đối với mô hình dự báo về tần suất TNGT, các thuật toán của học máy được sử dụng bao gồm mạng nơ-ron nhân tạo (Chang 2005; Xie et al. 2007; Çodur et al. 2015), cây hồi quy và phân loại (Chang and Chen, 2005) và máy vector hỗ trợ (Li et al. 2008). Cụ thể, mỗi thuật toán của học máy như sau:
- Mạng nơ-ron nhân tạo, Artificial neural network (ANN) là một mô hình xử lý thông tin mô phỏng theo các thức xử lý thông tin của các hệ nơ-ron sinh học. Nó được tạo nên từ một số lượng lớn các phần tử kết nối với nhau qua các liên kết (gọi là trọng số liên kết) làm việc như một thể thống nhất để giải quyết một vấn đề cụ thể nào đó (Nguyên et al.2017; Vanneschi et al. 2018). Mạng nơ-ron nhân tạo bao gồm có lớp đầu vào (input slayer), lớp đầu ra (oput layer) và các lớp ẩn (hidden layers). Ngoài ra, giữa các lớp trong mạng nơ-ron nhân tạo được liên kết bằng các trọng số liên kết và hàm chuyển đổi (Hình 2a).
- Máy vector hỗ trợ, Support Vector Machine (SVM), là một thuật toán học có giám sát của học máy. Mục đích của máy vector hỗ trợ để xác định một siêu phẳng có (n - 1) chiều trong không gian n chiều của dữ liệu sao cho siêu phẳng này phân loại các lớp một cách tối ưu nhất. Nói cách khác, cho một tập dữ liệu có nhãn, thuật toán sẽ dựa trên dữ liệu học để xây dựng một siêu phẳng tối ưu được sử dụng để phân loại dữ liệu mới (Jakkula 2011; Awad et al. 2015; Thị et al. 2013). Mô hình của máy véctơ hỗ trợ được thể hiện trong Hình 2b.
- Cây hồi quy và phân loại, Classification and regression tree (CART): Là một thuật toán học có giám sát để phân loại và hồi quy. Đối với việc phân loại, thuật toán này xây dựng một cây nhị phân với các nút gốc ban đầu, các nút quyết định và nút cuối. Mỗi nút gốc ban đầu và nút quyết định đại diện cho một đặc tính và giá trị ngưỡng của đặc tính đó. Đối việc hồi quy, thì dự đoán cuối là giá trị trung bình của các giá trị được gắn nhãn (Berk et al. 2008).
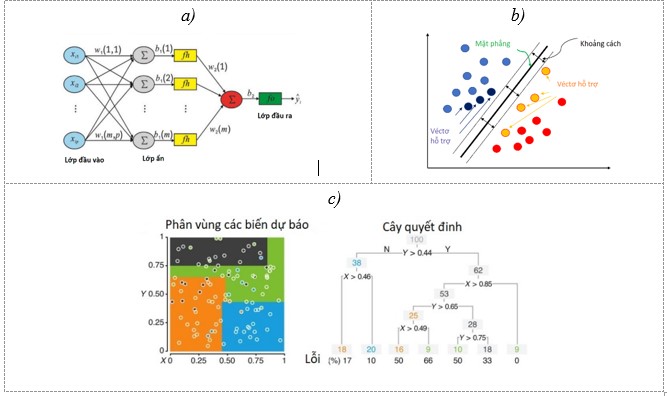
Hình 2: a) Mạng nơ-ron nhân tạo (Silva et al. 2020), b) Máy vector hỗ trợ (Manjrekar et al. 2019) , (c) Cây hồi quy và phân loại (https://www.nature.com)
* Mô hình sự báo về mức độ nghiêm trọng của TNGT:
Trên thế giới, mức độ nghiêm trọng của TNGT được chia thành cấu trúc đơn biến và cấu trúc đa biến. Đối với cấu trúc đơn biến, mức độ nghiêm trọng của TNGT được bao gồm hai mức là tai nạn có thương vong và tai nạn chỉ thiệt hại về vật chất. Đối với cấu trúc đa biến, mức độ nghiêm trọng cuả TNGT bao không thương vong, tử vong, thương nhẹ. Tại Việt Nam, mức độ nghiêm trọng của TNGT được chia thành có tử vong và thương vong trong các báo cáo của các cơ quan quản lý nhà nước. Hiện nay, các nghiên cứu tập trung vào khám phá các kỹ thuật khác nhau để cố gắng cải thiện kỹ thuật đơn giản bằng cách thay đổi cấu trúc của nó, thuật toán đào tạo, hàm quy luật hoặc sử dụng thuật toán phân nhóm.
Để dự báo về mức độ nghiêm trọng của các TNGT, các thuật toán chính của máy học được sử dụng trong mô hình dự báo về mức độ nghiêm trọng của tai nạn bao gồm Mạng nơ-ron nhân tạo (Abdel-Aty et al. 2003; Delen et al. 2006; Amiri et al. 2020), cây quyết định (Kwon et al. 2015; Wahab et al. 2019), Mạng Bayes (De Oña, et al. 2011; De Oña et al. 2013), Máy vectơ hỗ trợ (Iranitalab et al. 2017; Zhang et al. 2018), Thuật toán Random forest (Iranitalab et al. 2017; Zhang et al. 2018; Wahab et al. 2019), Thuật toán láng giềng gần nhất K (Iranitalab et al. 2017; Zhang et al. 2018; Wahab et al. 2019), cây hồi quy và phân loại (Chang et al. 2006; Kashani c 2011) và and hybrid intelligent genetic algorithm (Amiri et al. 2020). Các thuật toán về mạng nơ-ron nhân tạo, máy vector hỗ trợ và cây hồi quy và phân loại đã được trình bày ở trên. Dưới đây trình bày các thuật toán còn lại của học máy trong mô hình dự báo về mức độ nghiêm trọng của tai nạn như sau:
- Cây quyết định, Decision Tree (DT) là một mô hình học có giám sát, có thể được áp dụng vào cả hai bài toán hồi quy và phân loại. Việc xây dựng một cây quyết định trên dữ liệu huấn luyện cho trước là việc đi xác định các câu hỏi và thứ tự của chúng (Hình 3a). Cây quyết định có thể làm việc với các đặc trưng thường được gọi là thuộc tính dạng rời rạc và không có thứ tự.
- Mạng Bayes, Bayesian Network (BN) là một mô hình đồ họa xác xuất để biểu diễn kiến thức về miền không chắc chắn trong đó mỗi nút của mạng tương ứng với mỗi biến ngẫu nhiên và mỗi cạnh biểu thị xác xuất có điều kiện cho các biến ngẫu nhiên tương ứng (Hình 3b). Mô hình đồ họa của thuật toán này thể hiện mối quan hệ xác xuất nhân quả giữa các biến và thường được sử dụng để hỗ trợ việc ra quyết định. Các mối quan hệ xác xuất trong mạng Bayes có thể được hình thành bởi dữ liệu sẵn có hoặc đề xuất của chuyên gia (Thao et al. 2021).
- Thuật toán Random Forest (RF), là thuật toán phân loại có kiểm định dựa trên cây quyết định và kỹ thuật bagging và bootstrapping được cải tiến. Bootstrapping được thực hiện từ một quần thể ban đầu lấy ra một mẫu gồm n thành phần để tính toán các tham số mong muốn. Phương pháp Bagging được xem như là một phương pháp tổng hợp kết quả có được từ các bootstraping sau đó huấn luyện mô hình từ các mẫu ngẫu nhiên này và cuối cùng đưa ra dự đoán phân loại dựa vào số phiếu bầu cao nhất của lớp phân loại cây quyết định là một sơ đồ phát triển có cấu trúc dạng cây phân nhánh đi từ gốc cho đến lá, giá trị các lớp phân loại của mẫu được đưa vào kiểm tra trên cây quyết định (Rumao et al. 2019; Hương et al. 2018). Thuật toán Random Forest (RF) được thể hiện trong Hình 3c.
- Thuật toán láng giềng gần nhất K, K-nearest neighbor (KNN), là một trong những thuật toán của học có giám sát trong học máy. Khi thực hiện huấn luyện, thuật toán này không học một điều gì từ dữ liệu huấn luyện và mọi tính toán được thực hiện khi nó cần dự đoán kết quả của dữ liệu mới. K-nearest neighbor có thể áp dụng được vào hai loại của bài toán học có giám sát và áp dụng cho cả phân loại và hồi quy (Hình 3d).
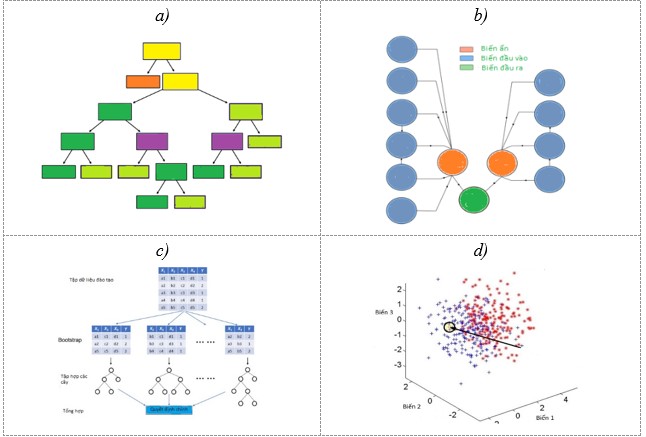
Hình 3: a) Cây quyết định; b) Mạng Bayes; c) Thuật toán Random Forest; d) Thuật toán láng giềng gần nhất K
Đánh giá hiệu quả học máy đối với phát triển các mô hình dự báo TNGT
Các nghiên cứu trên thế giới đã tiến hành so sánh hiệu quả giữa mô hình dự báo thống kê truyền thống và các mô hình dự báo sử dụng học máy thông qua độ chính xác của dự báo, sai số bình phương trung bình (MSE) và độ lệch tuyệt đối trung bình của mô hình. Kết quả của các nghiên cứu cho thấy rằng, hiệu quả của mô hình dự báo sử dụng học máy tốt hơn mô hình thống kê truyền thống trong cả mô hình dự báo về tần suất TNGT và mô hình dự báo về mức độ nghiêm trọng của TNGT, cụ thể:
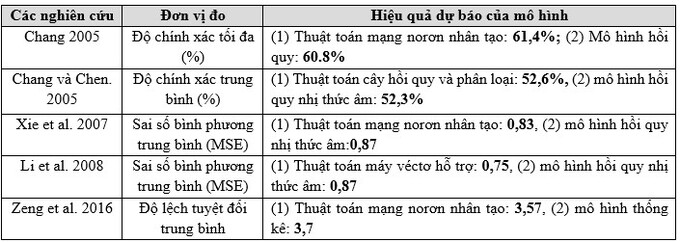
- Đối với mô hình dự báo về tần suất TNGT, các nghiên cứu (Chang 2005; Li et al. 2008; Xie et al. 2007; Zeng et al. 2016) đã tiến hành so s ánh giữa mô hình dự báo sử dụng học máy với các mô hình hồi quy nhị thức âm, mô hình hồi quy Possion và cho thấy rằng hiệu quả của mô hình sử dụng học máy là tốt hơn so với các mô hình thống kê truyền thống này (Bảng 1).
Bảng 1. So sánh giữa các mô hình sử dụng máy học và mô hình thống kê truyền thống về dự báo tần suất TNGT
- Đối với mô hình dự báo về mức độ nghiêm trọng của TNGT, các nghiên cứu (Kwon et al. 2015; Zhang et al. 2018; Wahab et al. 2019) cũng đã tiến hành so sánh giữa mô hình dự báo sử dụng học máy với các mô hình truyền thống như mô hình Logit, mô hình hồi quy đa biến; kết quả cũng chỉ ra rằng mô hình sử dụng học máy là tốt hơn so với các mô hình thống kê truyền thống này (bảng 2) trong dự báo về mức độ nghiêm trọng của TNGT.

Bảng 2. So sánh giữa các mô hình sử dụng máy học và mô hình thống kê truyền thống về dự báo về mức độ nghiêm trọng của TNGT
Trong các nghiên cứu cũng chỉ ra rằng, mạng nơ-ron nhân tạo là một thuật toán phù hợp nhất và được ứng dựng nhiều trong mô hình dự báo về tần suất TNGT (Silva et al. 2020). Ngoài ra, mạng nơ-ron nhân tạo cũng hữu ích trong các mô hình dự báo về mức độ nghiêm trọng của TNGT. Trong mô hình dự báo về mức độ nghiêm trọng, thuật toán Random Forest là tốt nhất so với thuật toán khác của học máy trong dự đoán về mức độ nghiêm trọng của TNGT (Silva et al. 2020).
Kết luận
Cùng với xu hướng phát triển của cuộc các mạng công nghiệp 4.0, việc ứng dụng trí tuệ nhân tạo AI và cụ thể là học máy vào lĩnh vực ATGT là hết sức cần thiết nhằm giảm thiểu TNGT. Một trong ứng dụng của học máy là phát triển các mô hình dự báo về TNGT, giúp các cơ quan quản lý nhà nước xác định được các yếu tố quan trọng gây ra TNGT và dự báo về tần suất và mức độ nghiêm trọng của TNGT để đưa ra các giải pháp và chính sách phù hợp.
Từ các nghiên cứu trên thế giới, có thể thấy rằng hiệu quả của mô hình sử dụng học máy tốt hơn mô hình thống kê truyền thống để dự báo TNGT. Vì vậy, trong bài báo này, tác giả đề xuất cần phải triển khai nghiên cứu và áp dụng mô hình sử dụng học máy vào dự đoán về tần suất và mức độ nghiêm trọng TNGT tại Việt Nam. Ngoài ra, tác giả cũng đề xuất áp dụng thuật toán mạng nơ-ron nhân tạo của máy học cho mô hình dự báo về tần suất TNGT và thuật toán Random Forest của máy học cho mô hình dự báo về mức độ nghiêm trọng của TNGT.
Tuy nhiên, để có thể áp dụng hiệu quả được học máy vào các mô hình dự báo TNGT, Việt Nam cũng cần phải có dữ liệu đầy đủ và chi tiết về TNGT như vị trí tai nạn, thời điểm xảy ra tai nạn, mức độ nghiêm trọng của tai nạn, điều kiện thời tiết...
KS. Bùi Tiến Mạnh
Trường Đại học Công nghệ Nagaoka
Tag:




Bình luận
Thông báo
Bạn đã gửi thành công.